Tools and Infrastructure
This project assembles and interconnects many of the technical parts that are collectively used in Experiences’ deployments. It creates interactions that help people handle the complexity of management, analysis and change in software and its use. It makes accessible the algorithmic advances of Inference Methods and Formal Analysis, and the conceptual advances of Conceptual Frameworks.
Logging
All our released apps are instrumented with logging code, to capture how users interact with the apps. We have rebuilt our logging infrastructure to be more flexible, via a publish-subscribe architecture that allows multiple consumers of log data to work relatively independently—instead of the one monolithic service we previously relied on. A sketch of the components involved in the infrastructure is seen below.
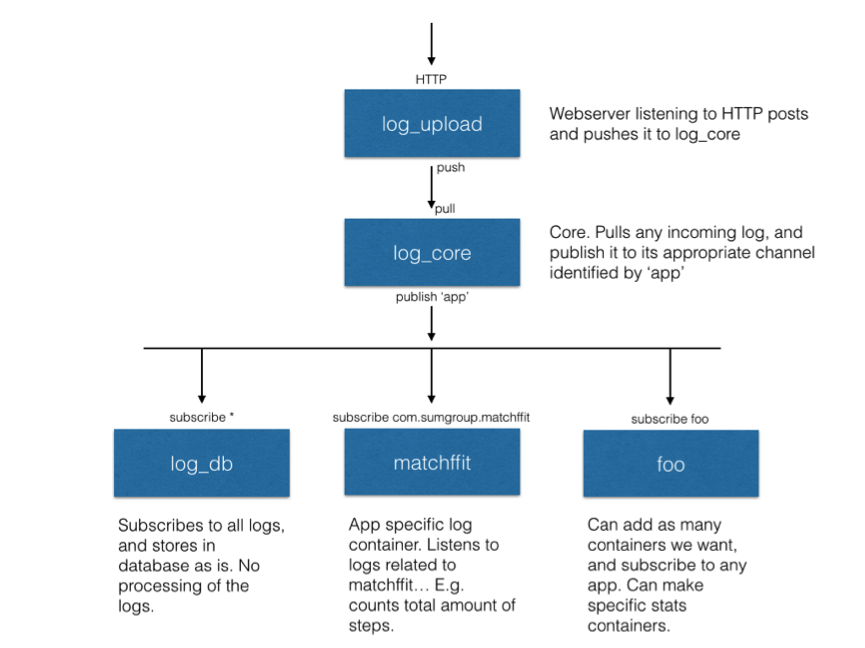
The logging infrastructure is built up of Docker containers. Docker containers are small Linux-containers that are most easily understood as lightweight virtual machines running on a host machine. Docker containers communicate through standard TCP/IP networking, a communications paradigm deeply integrated in Linux environments. Instead of raw socket communication, the infrastructure uses ZeroMQ, which abstracts asynchronous socket based data passing between machines and processes.
Analysis Tools
We have developed Blocks, a meta-tool for creating exploratory data analysis tools that allow us to analyse app usage from app logs. It aims to allow for the integration of analysis methods and tools developed in the Inference Methods and Formal Analysis parts of the project, to make these tools available for developers and analysts who are not bona fide statisticians/formalists, and to allow for the implementation of visualisations on top of these statistical/formal tools. It further allows users of the resulting tools to do more interaction with the data than is typical in mainstream statistical/formal tools. This is thus different from creating reports from data. Rather the resulting tool provides a starting point for an ongoing analysis of the data, and allows the user not only to interact with the data and the analysis, but to extend the analysis and the visualisations thereof.
Blocks in its current form is a web application running in the browser. Users of Blocks write series of small snippets of code. These snippets of code can typically be of four types
- Data block: a block for getting data into the project (e.g. a MySQL statement for selecting rows in a table for analysis)
- Filter block: a block for filtering data based on input parameters or other collections of data (e.g. filter data on a set of users)
- Visualization block: for visualizing a collection of data (e.g. render bar chart)
- Analysis block: code that does analysis on the incoming data
Blocks are generally written in JavaScript and run natively in the web browser. However, Blocks is intended to be easily extensible with existing tools and libraries written in other languages than JavaScript or runnable in a browser. For instance data blocks can be written directly in MySQL to fetch data from a MySQL server. Certain analysis blocks are written in Python, PRISM, or even more specific programs such as Mallet—an implementation of Latent Dirichlet Allocation (LDA). This extensibility of Blocks lets us implement a bridge between other languages and the browser environment. Implementing this bridge can turn a machine learning library into an interactive component usable within Blocks to explore data.